This blog post doesn’t want to be an exhaustive tutorial to describe the way to go for having Apache Kafka deployed in an OpenShift or Kubernetes cluster but just the story of my journey for having a “working” deployment and using it as a starting point to improve over time with a daily basis work in progress. This journey started using Apache Kafka 0.8.0, went through 0.9.0, finally reaching the nowadays 0.10.1.0 version.
From “stateless” to “stateful”
One of the main reasons to use a platform like OpenShift/Kubernetes (let me to use OS/K8S from now) is the scalability feature we can have for our deployed applications. With “stateless” applications there are not so much problems to use such a platform for a Cloud deployment; every time an application instance crashes or needs to be restarted (and/or relocated to a different node), just spin up a new instance without any relationship with the previous one and your deployment will continue to work properly as before. There is no need for the new instance to have information or state related to the previous one.
It’s also true that, out there, we have a lot of different applications which need to persist state information if something goes wrong in the Cloud and they need to be restarted. Such applications are “stateful” by nature and their “story” is important so that just spinning up a new instance isn’t enough.
The main challenges we have with OS/K8S platform are :
- pods are scaled out and scaled in through Replica Sets (or using Deployment object)
- pods will be assigned an arbitrary name at runtime
- pods may be restarted and relocated (on a different node) at any point in time
- pods may never be referenced directly by the name or IP address
- a service selects a set of pods that match specific criterion and exposes them through a well-defined endpoint
All the above considerations aren’t a problem for “stateless” applications but they are for “stateful” ones.
The difference between them is also know as “Pets vs Cattle” meme, where “stateless” applications are just a herd of cattle and when one of them die, you can just replace it with a new one having same characteristics but not exactly the same (of course !); the “stateful” applications are like pets, you have to take care of them and you can’t just replace a pet if it’s die 😦
Just as reference you can read about the history of “Pets vs Cattle” in this article.
Apache Kafka is one of these type of applications … it’s a pet … which needs to be handle with care. Today, we know that OS/K8S offers Stateful Sets (previously known as Pet Sets … for clear reasons!) that can be used in this scenario but I started this journey when they didn’t exist (or not released yet), so I’d like to share with you my story, the main problems I encountered and how I solved them (you’ll see that I have “emulated” something that Stateful Sets offer today out of box).
Let’s start with a simple architecture
Let’s start in a very simple way using a Replica Set (only one replica) for Zookeeper server and the related service and a Replica Set (with three replicas) for Kafka servers and the related service.

The Kafka Replica Set has three replicas for “quorum” and leader election (even for topic replication). The Kafka service is needed to expose Kafka servers access even to clients. Each Kafka server may need :
- unique ID (for Zookeeper)
- advertised host/port (for clients)
- logs directory (for storing topic partitions)
- Zookeeper info (for connection)
The first approach is to use the broker id dynamic generation so that when a Kafka server starts and needs to connect to Zookeeper, a new broker id is generated and assigned to it. The advertised host/port are just container IP and the fixed 9092 port while the logs directory is predefined (by configuration file). Finally, the Zookeeper connection info are provided through the related Zookeeper service using the related environment variables that OS/K8S creates for us (ZOOKEEPER_SERVICE_HOST and ZOOKEEPER_SERVICE_PORT).
Let’s consider the following use case with a topic (1 partition and 3 replicas). The initial situation is having Kafka servers with broker id 1001, 1002, 1003 and the topic with current state :
- leader : 1001
- replicas : 1001, 1002, 1003
- ISR : 1001, 1002, 1003
It means that clients need to connect to 1001 for sending/receiving messages for the topic and that 1002 and 1003 are followers for having this topic replicated handling failures.
Now, imagine that the Kafka server 1003 crashes and a new instance is just started. The topic description becomes :
- leader : 1001
- replicas : 1001, 1002, 1003 <– it’s still here !
- ISR : 1001, 1002 <– that’s right, 1003 is not “in-sync”
Zookeeper still sees the broker 1003 as a host for one of the topic replicas but not “in-sync” with the others. Meantime, the new started Kafka server has a new auto generated id 1004. A manual script execution (through the kafka-preferred-replica-election.sh) is needed in order to :
- adding 1004 to the replicas
- removing 1003 from replicas
- new leader election for replicas

So what does it mean ?
First of all, the new Kafka server instance needs to have the same id of the previous one and, of course, the same data so the partition replica of the topic. For this purpose, a persistent volume can be the solution used, through a claim, by the Replica Set for storing the logs directory for all the Kafka servers (i.e. /kafka-logs-<broker-id>). It’s important to know that, by Kafka design, a logs directory has a “lock” file locked by the server owner.
For searching for the “next” broker id to use, avoiding the auto-generation and getting the same data (logs directory) as the previous one, a script (in my case a Python one) can be used on container startup before launching the related Kafka server.
In particular, the script :
- searches for a free “lock” file in order to reuse the broker id for the new Kafka server instance …
- … otherwise a new broker id is used and a new logs directory is created
Using this approach, we obtain the following result for the previous use case :
- the new started Kafka server instance acquires the broker id 1003 (as the previous one)
- it’s just automatically part of the replicas and ISR

But … what on Zookeeper side ?
In this deployment, the Zookeeper Replica Set has only one replica and the service is needed to allow connections from the Kafka servers. What happens if the Zookeeper crashes (application or node fails) ? The OS/K8S platform just restarts a new instance (not necessary on the same node) but what I see is that the currently running Kafka servers can’t connect to the new Zookeeper instance even if it holds the same IP address (through the service usage). The Zookeeper server closes the connections after an initial handshake, probably related to some Kafka servers information that Zookeeper stores locally. Restarting a new instance, this information are lost !
Even in this case, using a persistent volume for the Zookeeper Replica Set is a solution. It’s used for storing the data directory that will be the same for each instance restarted; the new instance just finds Kafka servers information in the volume and grants connections to them.

When the Stateful Sets were born !
At some point (from the 1.5 Kubernetes release), the OS/K8S platform started to offer the Pet Sets then renamed in Stateful Sets like a sort of Replica Sets but for “stateful” application but … what they offer ?
First of all, each “pet” has a stable hostname that is always resolved by DNS. Each “pet” is being assigned a name with an ordinal index number (i.e. kafka-0, kafka-1, …) and finally a stable storage is linked to that hostname/ordinal index number.
It means that every time a “pet” crashes and it’s restarted, the new one will be the same : same hostname, same name with ordinal index number and same attached storage. The previous running situation is fully recovered and the new instance is exactly the same as the previous one. You could see them as something that I tried to emulate with my scripts on container startup.
So today, my current Kafka servers deployment has :
- a Stateful set with three replicas for Kafka servers
- an “headless” service (so without an assigned cluster IP) that is needed for having Stateful set working (so for DNS hostname resolution)
- a “regular” service for providing access to the Kafka servers from clients
- one persistent volume for each Kafka server with a claim template defined in the Stateful set declaration
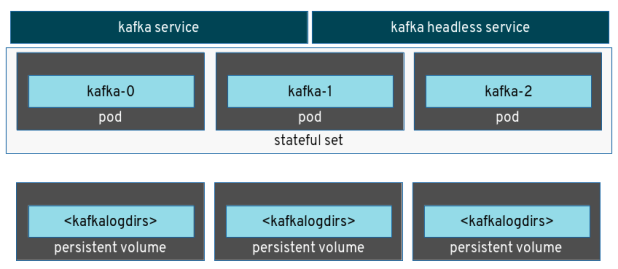
Other then to use a better implementation 🙂 … the current solution doesn’t use a single persistent volume for all the Kafka servers (having a logs directory for each of them) but it’s preferred to use a persistent storage dedicated to only one “pet”.
It’s great to read about it but … I want to try … I want to play !
You’re right, I told you my journey that isn’t finished yet but you would like to try … to play with some stuff for having Apache Kafka deployed on OS/K8S.
I called this project Barnabas like one of the main characters of the author Franz Kafka who was a … messenger in “The Castel” novel :-). It’s part of the bigger EnMasse project which provides a scalable messaging as a service (MaaS) infrastructure running on OS/K8S.
The repo provides different deployment types : from the “handmade” solution (based on bash and Python scripts) to the current Stateful Sets solution that I’ll improve in the coming weeks.
The great thing about that (in the context of the overall EnMasse project) is that today I’m able to use standard protocols like AMQP and MQTT to communicate with an Apache Kafka cluster (using an AMQP bridge and an MQTT gateway) for all the use cases where using Kafka makes sense against traditional messaging brokers … that from their side have to tell about a lot of stories and different scenarios 😉
Do you want to know more about that ? The Red Hat Summit 2017 (Boston, May 2-4) could be a good place, where me and Christian Posta (Principal Architect, Red Hat) will have the session “Red Hat JBoss A-MQ and Apache Kafka : which to use ?” … so what are you waiting for ? See you there !









