During the just passed Christmas holidays, I decided to spend the spare time for digging into the reactive programming paradigm, the “Reactive streams” manifesto and the related ReactiveX implementation (more specifically on the RxJava one).
This blog post doesn’t mean to be a discussion about what reactive streams are or what reactive programming is just because you can find a lot of really useful resources on these arguments on the Internet but, because I’m a messaging and IoT guy, during this article I’ll try to describe some (really trivial) thoughts I had “discovering” the reactive streams API and comparing them to the AMQP 1.0 protocol.
On December 30th, I tweeted …

As you can see, I defined AMQP 1.0 as a “reactive” protocol because I really found all the semantics and the related definitions from the reactive streams API in the AMQP 1.0 specification.
What I’m going to describe is a mapping at 20,000 feet without digging into all the possible problems we can encounter doing that, just because it seemed rather trivial to me; I’d like to open a discussion on it or giving inputs to the other people for thinking about that.
It could be useful when it comes to use a reactive programming model in a microservices based system where a “good” messaging protocol for supporting such a model is needed.
The Reactive Streams API
We know that AMQP 1.0 is really a peer-to-peer protocol so we can establish a communication between two clients directly or using an intermediary (one or more) such as a broker (for allowing store-and-forward) or a router (providing direct-messaging as well). In all these use cases, it’s always about having a “sender” and a “receiver” which can be just mapped to a “publisher” and a “subscriber” in reactive streams API terms (if you think about ReactiveX, then you know them as “observable” and “observer”).
The reactive streams API are defined with four main interfaces with some methods which can be mapped in terms of specific AMQP 1.0 “performatives”.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {}
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}
The above interfaces describes how a “subscriber” can subscribe in order to receive stream of events published by a “publisher” and how this one “pushes” events to the subscriber. The API also defines how it’s possible to for the subscriber to avoid being overwhelmed by events if it’s slower than the publisher, using a “request for events” mechanism on the subscription. Finally, the subscriber can be notified when the stream is completed (if it’s not infinite) or if an error occurred.
During this post I won’t consider the Processor interface which enables an entity to be both a “publisher” and “subscriber” and it’s mainly used for implementing “operators” in the stream processing chain.
Attaching as … subscribing
The Publisher interface provides a subscribe method which is called by the subscriber when it wants to start receiving all the published events on the related stream (in a “push” fashion).
If we assign a name to the stream which could be an “address” in AMQP terms, then such an operation could be an “attach” performative sent by the subscriber which acts as a receiver on the established link. In the opposite direction, the publisher can reply with an “attach” performative (on the same address) acting as a sender and this operation could be mapped as the onSubscribe method call on the Subscriber interface.
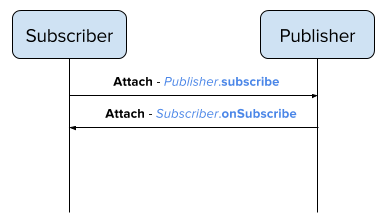
FIG.1 – attach as Publisher.subscribe, Subscriber.onSubscribe
Credits based flow control and transfer … for back-pressure and pushing events
One of the main reactive streams concepts which convinced me that AMQP is really a “reactive” protocol was the back-pressure. It provides a way for handling scenarios where a subscriber is slower than the publisher avoiding to be overwhelmed by a lot of events it can’t handle (losing them); the subscriber can notify to the publisher the maximum number of events it can receive. In my mind it’s something that AMQP provides out-of-box with the credits based flow control (something that it’s not available with the MQTT 3.1.1 protocol for example).
In terms of reactive streams API, such a feature is provided by the Subscription interface with the request method; calling this method, the subscriber says the maximum number of events to the publisher. In AMQP terms, it means that the receiver sends a “flow” performative specifying the credits number as the maximum number of messages it can handle in a specific moment in time.
At this point, the publisher can start to push events to the subscriber and it’s available through the onNext method call on the Subscriber interface. Even in this case, in AMQP terms, the sender starts to send one or more “transfer” performatives to the receiver with the message payload (representing the event).

FIG.2 – flow as Subscription.request(n) and transfer as Subscriber.onNext
Detaching … for cancelling, completed streams or errors
In order to complete this 20,000 feet mapping, there are few other methods provided by the reactive streams API I haven’t covered yet.
First of all, the subscriber can decide to not receiving events anymore calling the cancel method on the Subscription interface which in AMQP terms could be a simple “detach” performative sent by the receiver during the “normal” messages (events) exchanges.

FIG.3 – detach from receiver as Subscription.cancel
Finally, it’s important to remember that the reactive streams API takes into account finite streams of events and errors as well.
Regarding finite streams of events, the Subscriber interface exposes the onComplete method which is called when the publisher hasn’t no more events to push anymore so the streams is completed. In AMQP, it could mean a “detach” performative sent by the sender without any error conditions.

FIG.4 – detach from sender as Subscriber.onComplete
At same time, the reactive streams API defines a way to handle errors without catching exceptions but handling them as a special events. The Susbcriber interface provides the onError method which is called when an error happens and the subscriber is notified about that (in any case such an error is represented by a Throwable specific implementation). In AMQP, it could mean a “detach” performative sent by the sender (as it happens for a completed stream) but, this time, with an error condition providing specific error information.

FIG.5 – detach from sender as Subscriber.onError
Conclusion
Maybe you could have a different opinion (and I’d like to hear about that) but, at a first glance, it seemed to me that AMQP 1.0 is really THE protocol suited for implementing the reactive streams API and the related reactive programming paradigm when it comes to microservices in a distributed system and how to design their communication in a reactive way. It provides the main communication patters (request/reply but mainly publish/subscribe for this specific use case), it provides flow-control for the back pressure as well. It’s a really “push” oriented protocol compared to the “pull” HTTP nature for example. MQTT could be another protocol used in a reactive fashion but it lacks of flow-control (at least in the current 3.1.1 specification).