Almost one year and half ago, I started my journey about running Apache Kafka on Kubernetes and OpenShift. At that time, these containers orchestration platforms were focused on “stateless” (micro)services so there wasn’t a real support for a technology like Apache Kafka which is “stateful” by definition.
I wrote this blog post about my “investigation”, highlighting the problems to address in order to have Apache Kafka running on such a platforms. The solution was trying to “mimic” something that would have been added in the following months : the PetSets (then renamed in StatefulSets).
I created a new project named “Barnabas” (the name came from a character in a Franz Kafka novel; he was a messenger) with the objective to help developers on having resources (i.e. all needed YAML files) for deploying Apache Kafka on Kubernetes and OpenShift.
I got few people using “Barnabas” for their demos and proofs of concept receiving feedback and improvements; for example the Debezium team started to use it for deploying Apache Kafka with their supported Kafka Connect connectors; some people from the Aerogear project used it for some POCs as well.
Barnabas is died … long life to Strimzi !
Today … “Barnabas” isn’t here anymore 😦
It’s sad but it’s not so true ! It just has a new name which is Strimzi !

The objective here is always the same : providing a way to run an Apache Kafka cluster on Kubernetes and OpenShift. Of course, the project is open source and I hope that a new community can be born and grow around it : today I’m not the only one contributor and that’s great !
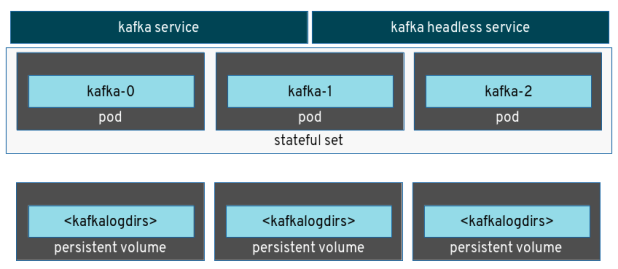
The current first early release (the 0.1.0) provides all the YAML resources needed for deploying the Apache Kafka cluster in terms of StatefulSets (used for the broker and Zookeeper nodes), Services (for having the nodes able to communicate each other and reachable by the clients), Persistent Volume Claims (for storing Kafka logs other then supporting “ephemeral” storage with emptyDir) and finally metrics support in order to get metrics data from the cluster through Prometheus and showing them in a Grafana dashboard.

Other than that, Strimzi provides a way for deploying Kafka Connect as well alongside a Kafka cluster. In order to simplify the addition of new connectors when running on OpenShift, the deployment leverage some unique OpenShift features like “Builds” and “S2I” images.
The future … is bright
While the current release already provides a simple way to deploy the Apache Kafka cluster (“templates” are also provided in the OpenShift use case) the future is rich of improvements and features we’d like to add.
First of all, we are working on not having these YAML resources anymore but using the “operator” approach (well known in the Kubernetes world).
Two main components will be part of such an approach in a short time : a cluster controller and a topic controller.
The cluster controller, running on Kubernetes (OpenShift), is in charge to deploy an Apache Kafka cluster based on the configuration provided by the user through a “cluster” ConfigMap resource. Its main work is to watch for a ConfigMap which contains the cluster configuration (i.e. number of broker nodes, number of Zookeeper nodes, healthcheck information, broker configuration properties, metrics configuration and so on) and then deploying the cluster based on such information. During its life, the cluster controller is also in charge to check updates on the ConfigMap and reflecting the changes on the already deployed cluster (i.e. the user increase the number of broker nodes in order to scale up the cluster or change some metrics parameters and so on).
The topic controller, always running on Kubernetes (OpenShift), provides a way to manage the Kafka topics without interacting with the Kafka brokers directly but using a ConfigMap approach. In the same way as the cluster controller, the topic controller is in charge to watch for specific ConfigMap resources which describe topics : this mean that a user can create a new ConfigMap containing topic information (i.e. name, number of partitions, replication factor and so on) and the topic controller will create the topic in the cluster. As already happens with the cluster controller, the topic controller is also in charge to check updates on the “topic” ConfigMap reflecting its changes to the cluster as well. Finally, this component is also able to handle scenarios where topics changes don’t happen on the ConfigMap(s) only but even directly into the Kafka cluster. It’s able to run a “3-way reconciliation” process in order to align topic information from these different sources.
Conclusion
Having these two components will be the next step for Strimzi in the short term but more improvements will come related to security, authentication/authorization and automatic cluster balancing where, thanks to the metrics, a cluster balancer will be able to balance the load across the different nodes in the cluster re-assign partitions when needed.
If you want to know more about the Strimzi project, you can engage with us in different ways, from IRC to the mailing list and starting following the official Twitter account. Thanks to its open source nature you can easily jump into the project providing feedback or opening issues and/or PRs … becoming a new contributor !
Looking forward to hear from you ! 😉
 Now we have broken something ! What ? Maybe you are asking …
Now we have broken something ! What ? Maybe you are asking …